Why good AI guidance in wealth management starts with the problem, not the model
A year ago, the fastest way to look innovative in wealth management was to bolt a chatbot about market commentary onto your product and call it AI. The market obliged. Tools were built, interest was assumed, and a strange focus formed around using AI to predict the market, reading sentiment and signals to drive transactions. The “AI model” was the product, and whoever had the most sophisticated one would win.
We don’t believe that.
And the reality only underscored the point. When capability is turned into a commodity and while the industry is still working out what makes commercial sense, the thing that sets you apart and stays consistent is the philosophy you encode into it.
The specific area we chose to focus on is helping a real person define a goal they can realistically fund, and understand more intuitively how to best use our platform, not producing more data for someone to process. As Morgan Housel puts it, the soft skills of money matter more than the technical side. A model that answers market questions well but doesn’t encourage good behaviour is more informational bloat in a domain that demands a fiduciary.

Today we’re launching EndowusAI in open beta for our Singapore users, three focused experiences built on an internal platform we call WealthWiseAI, designed around a single conviction. The job is to shape better decisions, not just produce more information.
Start with the problem, not the prompt

Over the years, we’ve observed what derails investors, and the failures tend to cluster into a few fundamental problems:
Before people have a portfolio problem, they have a goals problem. Most people can’t tell you, with any precision, what they’re investing for. They can’t say how much they’ll need, by when, or what they’d have to set aside to get there. Without that, every market wobble becomes a question of whether to keep going or divest. Decades of behavioural research, from Shefrin and Statman’s Behavioral Portfolio Theory to the multi-goal work of Das, Markowitz, Scheid, and Statman, show that when people name and separate their goals, they make structurally better choices, funding essential goals with safer, liquid assets and reserving higher-risk exposures for longer-horizon ambitions. The goal is foundational to make everything else legible.
This isn’t a new conviction for us. Goal-based investing has been ingrained in the Endowus approach from the start, and EndowusAI simply extends that same framing and helps to shape those goals through natural conversation.
People don’t lack data about their money, they lack clarity. The information exists, but it arrives in a language most people don’t speak. Statements, statuses, settlement, all technically available, but rarely add up to a confident sense of “here’s where my money is.” That gap between data and understanding is where anxiety grows, and this sort of anxiety is what drives the reactive behaviour that destroys both returns and trust. The work should then focus on translating these into plain language, where their money is and when it hits the market.
People want help, but they distrust help that can’t tell its own limits. Part of the problem is friction. Getting a straight answer has long meant hunting through FAQ pages, help centres, and support queues for something that should take seconds. People now expect to ask a question in plain language and get what they need immediately, in context, instead of digging for it. But convenience alone isn’t enough, because the moments that matter most are the ones where something has gone wrong. When that happens, what people want is a clear path to resolution and the certainty that a human will step in. A support experience that overreaches, that pretends to handle things it shouldn’t, erodes the exact trust it’s meant to build. The goal is help that is both effortless to reach and honest about its own boundaries.
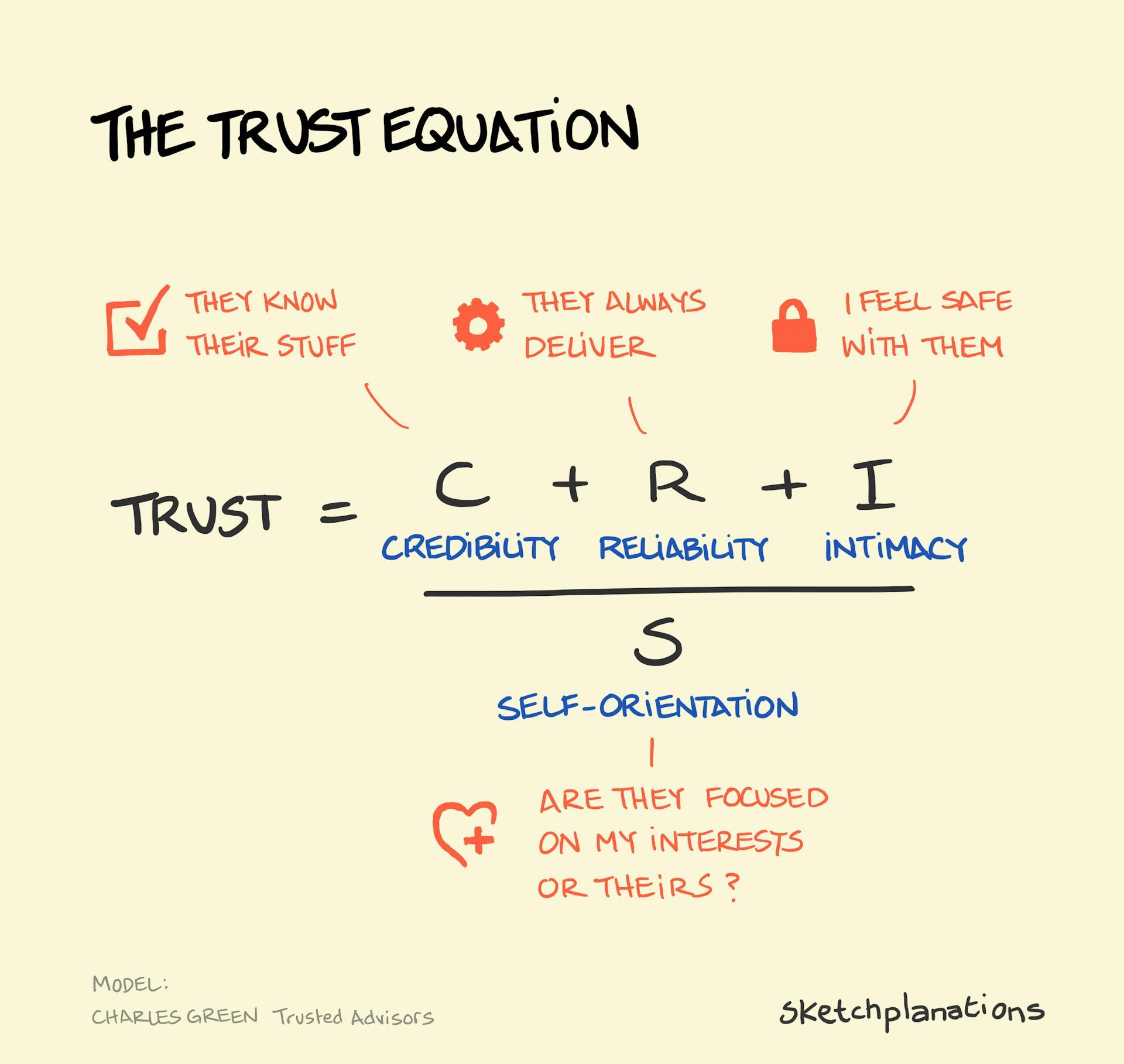
Three bots, three problems

1. The Goal Simulator Bot, for the goal definition problem
The Goal Simulator helps you formulate the foundation for a goal. It does not give specific financial advice. We chose to separate planning from monitoring. Whether something is “enough” or “on track” is a separate question, one we’re actively looking into, but it sits apart from the work of creating and defining a goal. That separation considerably simplifies the problem space we set out to address, while still leaving something comprehensible to present.
There are some principles we established when making this flow. The first is clarity over comfort. If something is worth flagging, it says so once, plainly and warmly, then respects your decision and moves on. The second is context over questions. When you don’t have a number, it gives you a reasonable one to react to rather than interrogating you for inputs you don’t have yet. The third is starting over perfecting, since a rough plan you can adjust beats a perfect plan you never begin. Moving from a vague aspiration to something actionable is what makes it a plan.
All these principles are in service to moving the client forward in their goal formation with sensitivity to what adjustments they might need to make.
2. The Transactions Bot, for the transaction clarity problem
The Transactions Bot answers a specific question. What is happening with my money right now? The data already exists in the app, but it’s expressed in operational terms, opaque statuses, settlement timelines, and industry-specific jargon that are precise for an operations team and meaningless to most clients. A UI can display that data, but it can’t interpret it for the person reading it. Static screens have to serve every user the same way, so they default to either oversimplified summaries or raw detail, and neither tells a client why their specific transfer is still pending three days in. This is something we really struggled with designing for as each person has a certain level of detail they need to feel comfortable. It translates the account activity into plain language, grounded in the client’s real records rather than a generic explanation, and it answers follow-up questions a fixed screen can’t anticipate. It won’t guess, and it won’t state a figure as fact unless it can stand behind it. When a question falls outside what it can confirm from the data, it escalates to a human rather than improvising an answer.
3. The Get Help Bot, for the platform knowledge and trust problem
The Get Help Bot is the front door to support, and it works two ways at once. It resolves what it can directly, answering platform and account questions up front instead of making you wait, while recognising that some situations still need a person. Trust depends on getting both sides right. Escalating everything is useless, but overreaching is worse, and people now expect a bot to know which is which. So it’s deliberately restrained about its own limits. It points you to the right place, whether that’s a direct answer, the right tool for account activity, or a person, and it escalates to our support team the moment a request calls for human judgement or you simply ask for someone. That’s our human-plus model, automation for scale and consistency, people for judgement and the moments that need them.
The road not taken

We seriously considered combining all three into a single general-purpose bot, and we may still examine it. For launch, keeping them distinct won out. A general bot carries the latency and complexity of every tool on every query, and it’s far harder to evaluate, because whether an answer is good gets tangled up with whether the bot even picked the right job to do. Effort goes into routing between scopes rather than doing each scope well.
Staying distinct also buys us clean measurement. We can see each bot’s impact on its own problem, but we still track how often one hands off to another, and watch where queries blur at the edges over time. That would clue us in on whether and when to combine them. The boundaries currently set aren’t dogma and we are constantly learning better frameworks to measure and adapt these bots.
Defining these bots and what we wanted them to do was the easy part. Now that we had an idea, we needed a way to build and govern them responsibly, and we needed a clear answer to a fundamental question. What should these AI bots not do? We’ll answer these separately.
Building a delivery system that works
A philosophy is only as good as your ability to enforce it at scale. You can write “evidence-based, goal-driven, transparent” on a wall, but unless those principles are encoded into the system and are tested with every response, they’re just cosmetic.

So before we shipped anything client-facing, we had been building WealthWiseAI for some time, a bespoke internal platform for configuring, evaluating, and comparing bots.
Speed without (or with limited) chaos. WealthWiseAI lets internal teams, not just engineers, compose, configure, and test their own bots. This was vital, because building the right experiences demanded close collaboration beyond product and engineering. Our client experience teams, the people closest to how our clients think, could shape and prototype bots directly rather than passing requirements down a chain. That turned bot development from a bottleneck into something closer to a shared workshop, where the people who understand client problems best build alongside the people who understand the technology.
Guardrails by default, not by reminder. The platform gates the things that should never be left to chance, from how personally identifiable information is handled to dangerous or out-of-scope queries and the suitability and regulatory boundaries we operate within (set by MAS in Singapore, SFC in Hong Kong). These aren’t checks we hope each bot remembers to run. They’re preset functionality every bot inherits.
Evaluation as a prerequisite to production. Comparing versions, measuring failure modes, and monitoring behaviour in production are built into the platform rather than improvised per project. This is what lets us iterate fast and sleep at night.
WealthWiseAI is the unglamorous half of this story, but it’s the half that makes the philosophy achievable. EndowusAI is what clients see, but WealthWiseAI is what helped us to evolve as quickly as we needed to, to keep up with industry trends and architectures and make that accessible to all internal builders.
We could write a whole article on why building our own system made sense, and we may. For now, we took the view that owning a platform let us build at speed and iterate where it mattered most, on the bot configurations themselves. It’s still an ongoing journey, and the platform is built to keep evolving.
What “agentic” should mean
This is the question that shaped what EndowusAI does, and what it does not.

“Agentic” has come to imply agency to act on your behalf, an AI that doesn’t just advise but executes, moves the money, pulls the trigger for you. The pitch is seductive and the technology is real.
Wealth management isn’t travel, and we’re not pretending the two are the same. But travel is further along in running the autonomous-agent experiment in public, and the behavioural signal coming out of it is worth paying attention to. We looked at it as an early read on how people respond when AI offers to act on their behalf.
What they found there was telling. Travellers are enthusiastic about AI for discovery and deeply reluctant to hand it the credit card. In Accenture’s research, only 32% of consumers would ask an agent to make a purchase decision after defining boundaries, and only about 9% are comfortable with AI deciding and buying fully autonomously. Skift’s reporting found leisure travellers even more cautious, with a tiny minority willing to let an agent book for them, and pinned the hesitation on a real gap, the absence of clear accountability when an autonomous booking goes wrong. Their conclusion was that pairing AI with human support, or even marketing human-led service as a differentiator, is becoming the smarter play rather than the fallback.
If travellers won’t let AI spend a few hundred dollars on a hotel without a human in the loop, then the idea that investors want a bot autonomously moving their investments is misreading what people want. And in a regulated, fiduciary domain, autonomy becomes incredibly risky.
So we made a deliberate choice. EndowusAI does not transact on your behalf. It helps you start, plan, calculate, and decide. This is a core design principle, not a limitation.
Chat to think, the UI to act
Deciding that the AI shouldn’t act for you raises a second question: where does the conversation end and the product begin?
Chat is a powerful way to think a problem through, but it is a poor place to take a consequential action. A wall of text is not where anyone wants to confirm a financial decision. Airbnb reached a similar conclusion from the interface side. Brian Chesky (CEO of Airbnb) has been explicit that he doesn’t think the chat experience is optimised for something like travel, where collaboration, map interfaces, and intuitive UI win out in several areas.
So rather than trying to do everything inside the conversation, EndowusAI hands off to the UI when it is time to act. The chat is used for what language is good at, unstructured research, planning, and iterative discussion, and then moves you to a purpose-built screen where you can see the numbers laid out and adjust them.
The discussion of AI versus UI is still ongoing. Embedded UI inside chat is an interesting space we’re exploring as well, and the industry is evolving, with consumers growing more used to chat over time, perhaps even voice. We will adapt when the time comes, but for now our stance is to balance the benefits of both worlds with what our platform does well today.
Bringing bots to market
Building responsibly and proving you’ve built responsibly are different things. In a regulated domain where a wrong answer can cost someone trust, money, or both, the bar for ready is high. An AI system also fails in ways you can’t fully enumerate in advance, so testing the handful of paths you thought of is never enough. You have to go looking for the failures.

We tried to break our own bots, on purpose.
We ran an internal “break the bot” challenge, turning the whole company loose on the system to find its failure points. A single team, however careful, can only imagine so many ways a conversation goes wrong, and the most damaging failures are usually the ones no one anticipated. Opening it up multiplied the number of people probing for cracks, and they were colleagues who knew where the product was weakest and where a client would feel it most. Honestly it was really fun. One of the categories was making it as least compliant-friendly as possible. Framing it as a challenge mattered more than it sounds, it turned a tedious but essential exercise into something people wanted to do, and spread an understanding of the bot’s limits across the company. It also found gaps where the experience could be more compelling, the kinds of things you stop noticing after 40+ iterations on a prompt.
We tested in the open, with real clients.
No internal exercise reproduces a real person with a real goal and real money on the line. A closed beta with a small group of clients showed us how the bots behaved in the wild, where people phrase things no script anticipates. It surfaced adoption signals, failure modes, and patterns that a test suite never could, and it told us whether the philosophy landed. Did coaching help or frustrate? Did the handovers build trust or break it? A small cohort contained the risk while we learned, and every session helped us refine our evaluation and monitoring tooling against real usage.
We ran evaluations, and evaluations of our evaluations.
The bots changed constantly through all of this, across internal testing, closed groups, and new model releases. Human testing only goes so far, though. Testers have limited time and unpredictable volume, so we leaned on evaluation test sets that tried both to achieve each bot’s goal and to derail it. As scope shifted, we had to keep moving the test sets, metrics, and scoring framework along with it, so each iteration was anchored to something we could compare against the last and tell whether we were improving. The trap we kept hitting was tuning the judges so tightly to the cases we cared about that they stopped generalising to new ones. So we kept humans in the loop checking whether real client entries were being scored sensibly, since bad scoring quietly corrupts every decision you make downstream.
None of this was a master plan. It was closer to a chef’s notes from tasting than a recipe book, adjusting as we went and arriving somewhere that worked. But a pattern did emerge. You can’t specify something this open-ended up front and then ship it and hope. You put a bounded version under pressure, adversarial first and then real, watch how it behaves, and improve from there. Observe friction, build a minimal intervention with guardrails, release to a cohort, then the iterative cycles of learn, refine, scale.
This is just how we framed it for ourselves. The industry is working hard to make AI products faster to build and ship, and most of that is genuinely useful. But in a regulated business, moving too fast carries a real and specific cost, and that shaped the pace we chose.
What we’re betting on

To be clear, this isn’t the finished answer, or even definitively the best approach. We’re betting it’s the best way to learn. By starting from the client’s problems and building specific bots encoded with our philosophy, we get something that drives real value now while teaching us how people actually choose to use it. Those signals are what will shape how we evolve, whether we consolidate or specialise further.
Fundamentally, this release is an experiment. Models will keep improving, but by anchoring on specific problems rather than on model sophistication, we can see what actually matters within each space, and that understanding carries across whatever comes next. What we learn compounds rather than resets every time the technology moves.
That’s the bet.